前言
搜集了别人总结的文章,加上自己做的小笔记,供复习查看用。
数据集
-
ImageNet ILSVC 2012: 标定每张图片中物体的类别。一千万图像,1000类
PASCAL VOC 2007: 标定每张图片中,物体的类别和位置,一万图像,20类 (VOC物体检测任务:如果某数据集包含了20个物体类别,则还需要加上背景类,总共21类)
R-CNN
这个博主写的文章,真的是很清晰啊,把所有不清楚的名词都解释好了~
RCNN-将CNN引入目标检测的开山之作 R-CNN论文详解
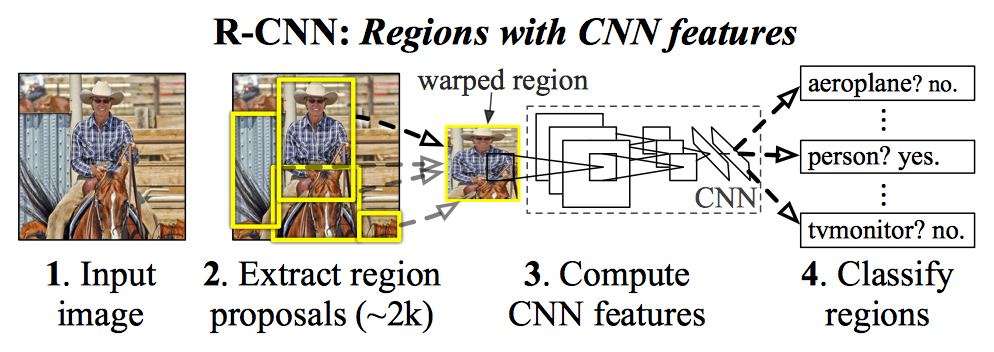
步骤:
1. 候选区域生成: 采用Selective Search的方法在一张图像生成1K~2K个候选区域(Region Proposal)
+ 此阶段搜索出来的候选框,大小各不相同,需要缩放(crop/warp)成227*227的固定尺寸
2. 特征提取: 将每个Region Proposal输入到CNN,将CNN的fc7层的输出作为特征
+ 网络设计:使用Alexnet,5层卷积2个全连接,f7的神经元个数都是4096,最后每个输入候选框图片都能得到一个4096维的特征向量
+ 网络有监督预训练阶段(ImageNet):标签较少,所以使用Alexnet直接初始化参数,SGD,lr = 0.001
+ fine-tuning阶段(PASCAL VOC):将上面预训练的最后一层替换成N+1个输出(N类再加一个背景,此处为21)。SGD,lr = 0.001,batch_size = 128(32个正样本,96个负样本)
+ 正负样本:一张图有2000个候选框,而人工标注只有正确的BBX。所以候选框与BBX的重叠区域IoU大于0.5,则视为正样本
3. 类别判断: 特征送入每一类的SVM分类器,判别是否属于该类
+ SVM训练阶段:
+ 检测窗口只包含部分物体,IoU的阈值为0.3,则小于0.3时为负样本。
+ 一旦CNN f7层特征被提取出来,则为每个物体类训练一个svm分类器。
+ 当我们用CNN提取2000个候选框,可以得到2000*4096这样的特征向量矩阵
+ 然后只需要把这样的一个矩阵与svm权值矩阵4096*N点乘(N为分类类别数目,因为我们训练的N个svm,每个svm包含了4096个权值w)。
+ 位置精修:目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤
+ 测试阶段:
+ 使用selective search的方法在测试图片上提取2000个region propasals ,将每个region proposals归一化到227x227,然后再CNN中正向传播,将最后一层得到的特征提取出来。
+ 然后对于每一个类别,使用为这一类训练的SVM分类器对提取的特征向量进行打分,得到测试图片中对于所有region proposals的对于这一类的分数,
+ 再使用贪心的非极大值抑制(NMS)去除相交的多余的框。再对这些框进行canny边缘检测,就可以得到bounding-box(then B-BoxRegression)。
4. 位置精修: 使用回归器精细修正候选框位置
相关的知识点:
+ selective search:将图像分割成小区域(1~2K个),按照规则(纹理、颜色等)合并相邻的两个区域,直到整个图像合并成一个区域位置。输出所有曾经存在过的区域,所谓候选区域
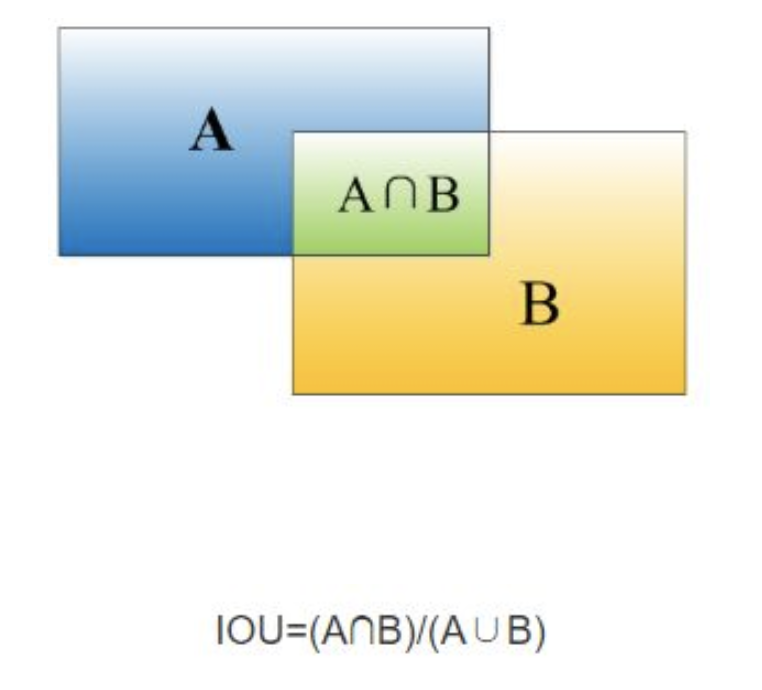
+ 重叠度(IOU):两个BBX的重叠度,即矩形框A、B的重叠面积占A、B并集的面积比例
+ 非极大值抑制(NMS):一张图片中找出N个可能是同一物体的矩形框,需要判别哪些框是没有用的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分`交叉`的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。
SPPNet
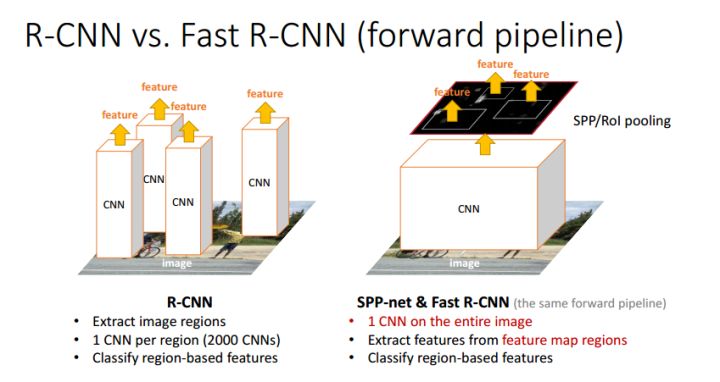
- 总体流程依旧是: Selective Search得到候选区域->CNN提取RoI特征->类别判断->位置精修
- 但是在faeture map上提取ROI特征,只需要在整张图像上做一次卷积,提高了效率

- 原始图像的RoI如何映射到特征图:原始图片中的ROI如何映射到到feature map?
- 感受野(receptive field,某一层
输出结果中一个元素所对应的输入层的区域大小)的计算:- 卷基层的输出:
output= ( input - kernel size + 2*padding ) / stride + 1 - 卷积层的输入:
input = (output - 1)* stride - 2*padding + kernel size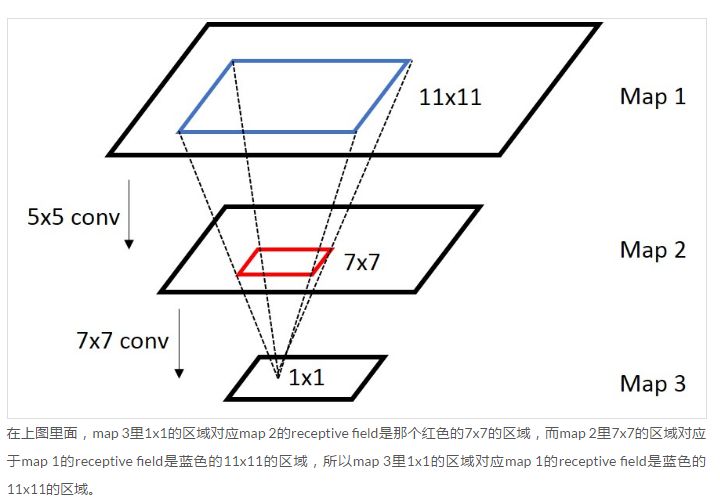
- 卷基层的输出:
- 上面只是给出了 前一层在后一层的感受野,如何计算最后一层在原始图片上的感受野呢? 从后向前级联一下就可以了(先计算最后一层到倒数第二层的感受野,再计算倒数第二层到倒数第三层的感受野,依次从后往前推导就可以了)
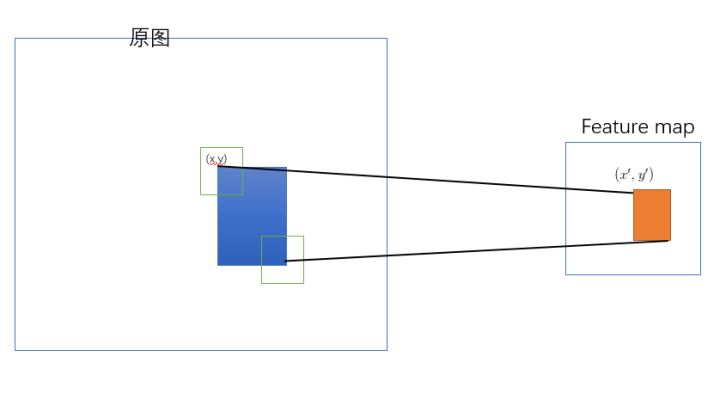
- SPP-net 是把原始ROI的左上角和右下角 映射到 feature map上的两个对应点。 有了feature map上的两队角点就确定了 对应的 feature map 区域(下图中橙色)。
- 感受野(receptive field,某一层
- RoI在特征图上对应的特征区域的维度不满足全连接层的输入要求
- 空间金字塔池化:假设原图输入是224x224,对于conv5出来后的输出是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。如果像下图那样将reponse map分成1x1(金字塔底座),2x2(金字塔中间),4x4(金字塔顶座)三张子图,分别做
max pooling后,出来的特征就是(16+4+1)x256 维度。如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256维度。这样就实现了不管图像尺寸如何 池化n 的输出永远是 (16+4+1)x256 维度。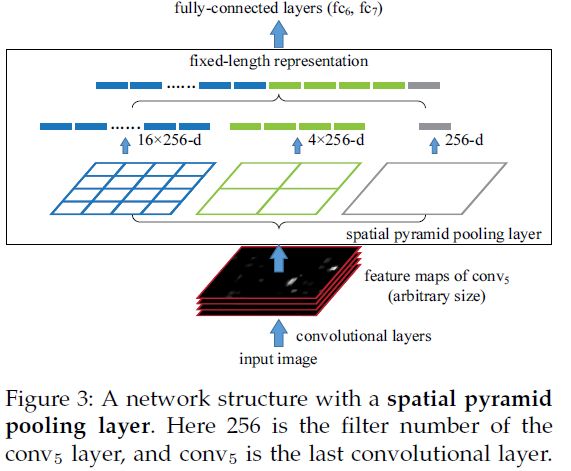
- 空间金字塔池化:假设原图输入是224x224,对于conv5出来后的输出是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。如果像下图那样将reponse map分成1x1(金字塔底座),2x2(金字塔中间),4x4(金字塔顶座)三张子图,分别做
Fast R-CNN
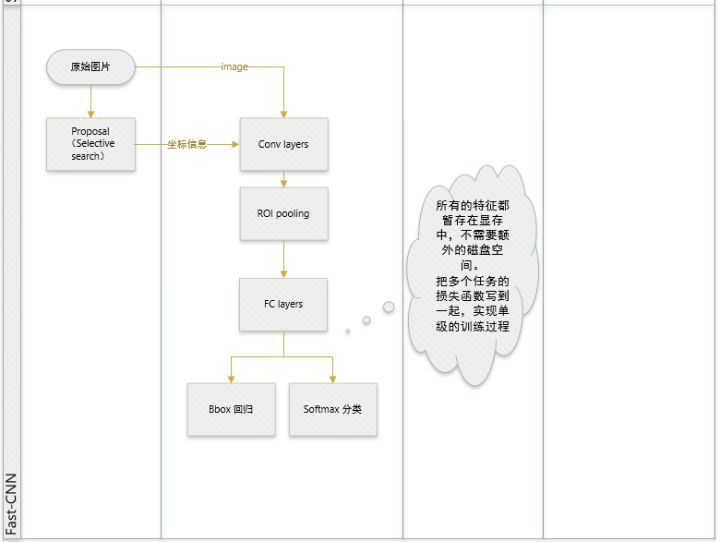
- joint training (SVM分类,bbox回归 联合起来在CNN阶段训练)把最后一层的Softmax换成两个,一个是对区域的分类Softmax(包括背景),另一个是对bounding box的微调。这个网络有两个输入,一个是整张图片,另一个是候选proposals算法产生的可能proposals的坐标。
- 提出了一个RoI层,算是SPP的变种,SPP是pooling成多个固定尺度,RoI只pooling到单个固定的尺度 (论文通过实验得到的结论是多尺度学习能提高一点点mAP,不过计算量成倍的增加,故单尺度训练的效果更好。)
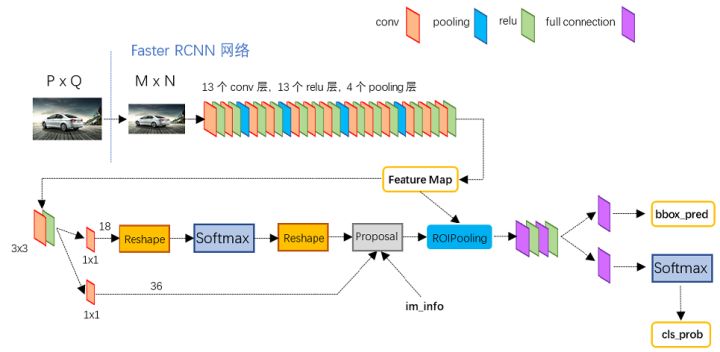
Faster R-CNN
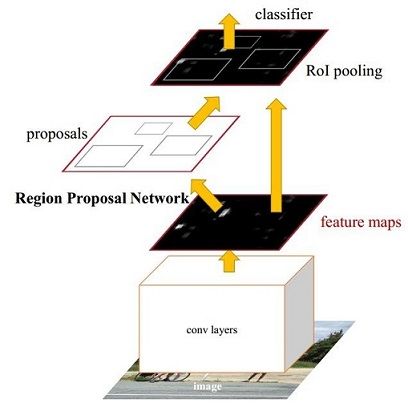
- 将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中
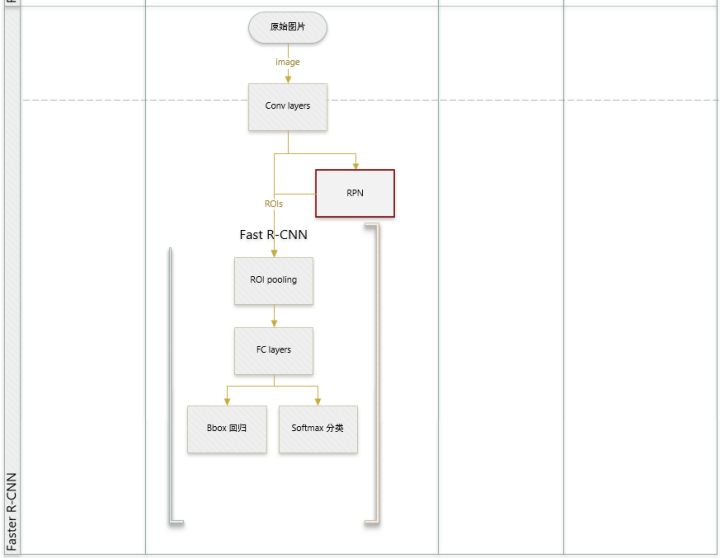 分为以下四步:
分为以下四步: - Conv layers。作为一种CNN网络目标检测方法,Faster R-CNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
- Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals。
- Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
- Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。